Selected reading about Dev, Ops, and Tech Debt
reading project management tech debtThis section has resources that I’ve found helpful for managing my own time, helping co-workers, and especially for working effectively with management and external teams.
Paul Graham’s Maker’s Schedule, Manager’s Schedule
A classic, and a great reason to cancel as many meetings as possible. I find that I do my best “deep work” either early in the morning, or late at night, mostly because there are no interruptions. Everyone has a different “cost” for context switching. Also note that this doesn’t just apply to scheduled meetings, unscheduled time in which you’re expected to be “available” and responsive on Slack can be just as disruptive.
I think there’s something to be said for the old paradigm of “If my office door is cracked, I’m interruptable for ad-hoc chats”, but I haven’t managed to re-create that in this world of open-plan seating and WFH.
Kalle Happonen’s 6 part series on “Agile Services”
This is a long series, and I’m working on a more in-depth post about it. Here, I mostly refer to sections Three: The Work, Four: The Team, and Five: Team Processes. The other sections were helpful for background, espectially as I don’t have much familiarity with scrum or similar methods.
My key takeaways so far:
- Existing agile methods for software development have challenges adapting to a mixed dev/ops work environment, due to the amount of unplanned work inherent.
- This unplanned work (fixing things that break, proactive maintenance) is very important, but also doesn’t produce much value, and needs to be minimized where possible. The Google SRE book refers to this as Toil.
- You need a team to support a production service. This means they must share responsiblity, and all be able to work on a common backlog of tasks to support said service. Having people on multiple teams is worse than having teams support multiple services, due to context switching and knowledge transfer.
- A couple of rotating roles are important: A Sheriff/Ticket Master role exists to shield the team from interruptions, responding to tickets, alerts, and other reactive issues during their shift. A reviewer ensures that the task backlog is healthy, so that the team can efficiently take tasks to do.
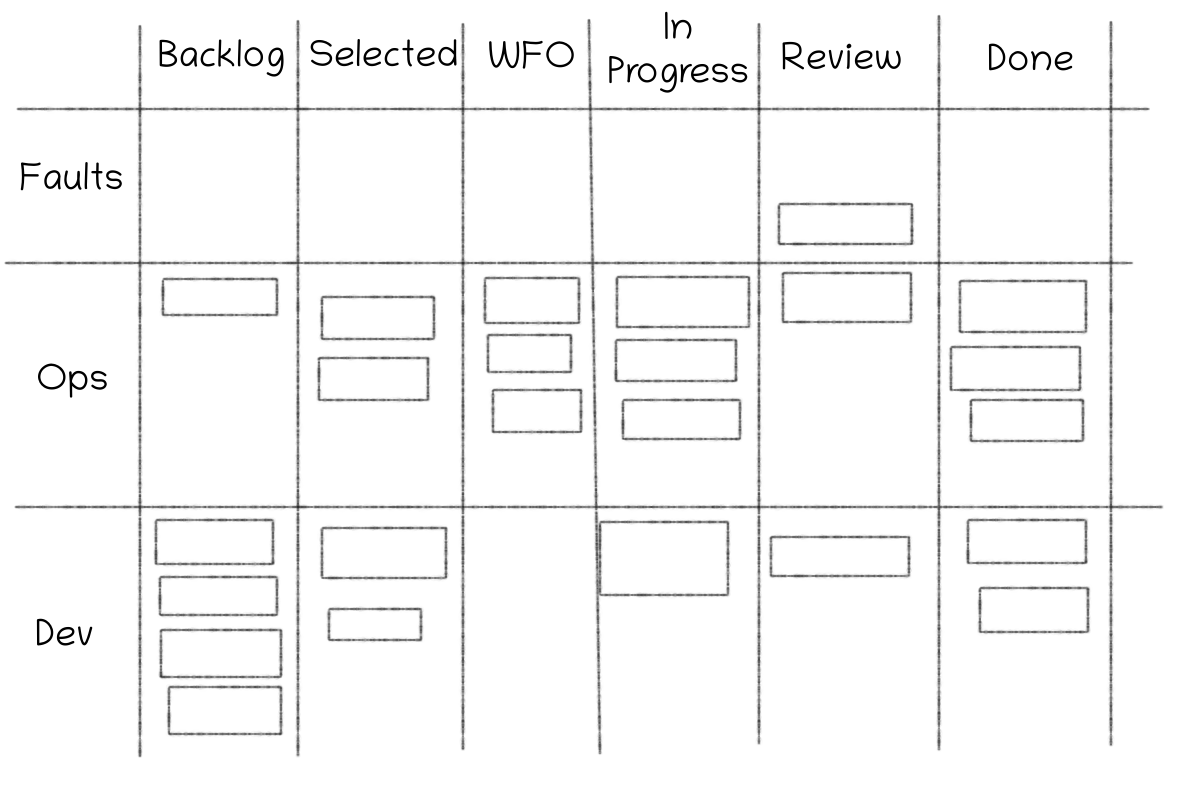
- Faults take priority over all other tasks, Ops tasks take priority over Development tasks. If you have so much ops that dev can’t happen, this is “Engineering Bankruptcy”, and you need to do something. A reasonable target is 50/50 ops to dev, while still getting all necessary ops done.
- It’s important to limit the number of tasks in progress at once. Therefore, we need a way to make all of these tasks visible, or we risk not accounting for them. I quite liked this Kanban Board for this purpose.
Further Reading
DevOps and SRE
- From Google’s SRE resource: On incidents
- Alerting and toil
- Implementing Service Level Objectives (Not SLAs!)
- Rob Ewaschuk’s My philosophy on alerting”
- The SRE book